在進行模型訓練時,通常會將資料切一小部分來進行驗證。驗證資料集通常可用來檢視訓練過程中模型是否不斷的進步,而如何切分資料及,則可以用數個交叉驗證的方法來進行。
在大部分的情況,資料會被切分出訓練資料集和測試資料集,在模型訓練時僅會使用訓練資料集,而測試資料集則被用來評估模型的表現,最理想的模型為在測試資料集且訓練資料集皆可以達到很好的表現。而交叉驗證的概念為將訓練資料集在進行切分,拿取部分資料作為驗證資料集,在模型訓練和參數調整時,使用驗證資料集進行驗證,確認該次迭代所計算出的損失函數是否有減少或其他模型衡量變數是否有較好的表現,在確認模型的表現達到該階段最佳時,便會使用測試資料集去檢查模型的表現,較常使用的交叉驗證法如下:

此方法為最易操作的交叉驗證,意即將資料按照比例分成三部分,訓練資料、驗證資料、測試資料。只有在訓練資料會放入模型進行訓練,其餘的兩部分則會拿來驗證模型的好壞。
K-fold Cross-Validation
圖片來源:連結
此方法目前較受到歡迎,k-fold的k代表的是將訓練資料切分為k組,每次將(k-1)組資料作為訓練資料,1組作為驗證資料,重複迭代k次。K的數量可根據資料數量來做決定。
Leave One Out Cross-Validation (LOOCV)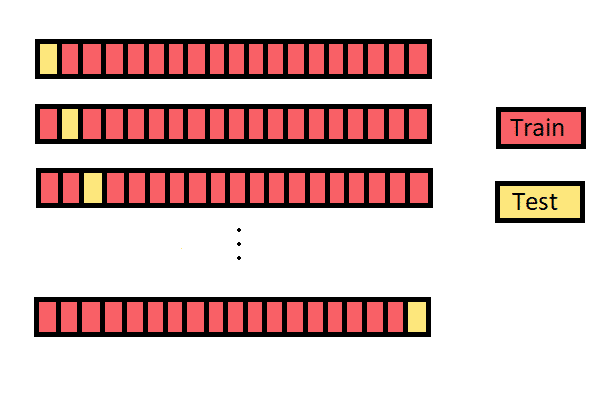
圖片來源:連結
此方法為k-fold cross-validation的特例,則是將k令為訓練資料集的總數量N,則在每次訓練時,僅會使用一筆資料來作為驗證資料,其餘的N-1筆會作為訓練資料放入模型當中。
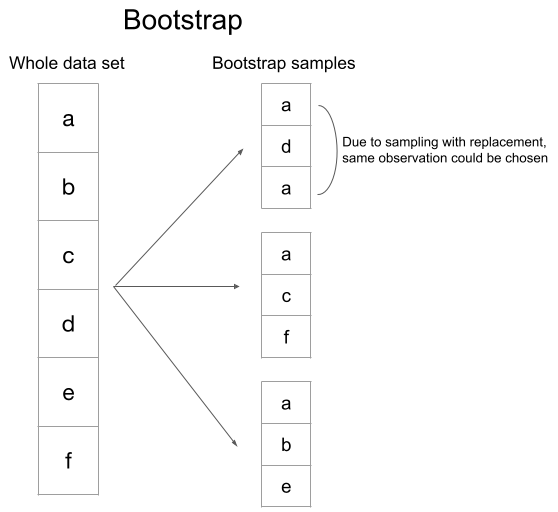
當使用此方法,可自行決定每次要從訓練資料中隨機抽取幾筆作為驗證資料,其餘未被抽取到的資料則視為訓練資料,由於是隨機抽取且取後放回的概念,因此在每次迭代中,可能會挑選到某些重複的樣本來作為驗證資料。
R: caret套件中createDataPartition
library(caret)
index <- createDataPartition(dataset2$Activity, p = 0.8, list =FALSE)
training_set <- dataset2[index,]
testing_set <- dataset2[-index,]
dim(training_set) # 972596 14
dim(testing_set) # 243149 14
Python: sklearn.model_selection套件中train_test_split
from sklearn.model_selection import train_test_split
X = dataset2.iloc[:,range(0,12)]
Y = dataset2['Activity']
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.2, random_state=0)
X_train.shape, Y_train.shape # ((972596, 12), (972596,))
X_test.shape, Y_test.shape #((243149, 12), (243149,))
R: caret套件中trainControl(method = "cv",number = k)
## 10-fold cross-validation
train_control <- trainControl(method = "cv",number = 10)
## 設定完train_control後,可使用train()來訓練模型,method可選擇想使用的模型
model <- train(Activity ~., data = dataset2, method = method,
trControl = train_control)
Python: sklearn.model_selection套件中KFold
from sklearn.model_selection import KFold
X = dataset2.iloc[:,range(0,12)]
Y = dataset2['Activity']
cv = KFold(n_splits=5)
for train, test in cv.split(X):
print("%s %s" % (train.shape, test.shape))
#(972596,) (243149,)
#(972596,) (243149,)
#(972596,) (243149,)
#(972596,) (243149,)
#(972596,) (243149,)
R: caret套件中trainControl(method = "cv",number = k,repeats = repeat_time)
## 10-fold, 3 times repetition
train_control <- trainControl(method = "repeatedcv",
number = 10, repeats = 3)
## 設定完train_control後,可使用train()來訓練模型,method可選擇想使用的模型
model <- train(Activity ~., data = dataset2, method = method,
trControl = train_control)
Python: sklearn.model_selection套件中RepeatedKFold
from sklearn.model_selection import RepeatedKFold
X = dataset2.iloc[:,range(0,12)]
Y = dataset2['Activity']
rcv = RepeatedKFold(n_splits=5, n_repeats=3)
for train, test in rcv.split(X):
print("%s %s" % (train.shape, test.shape))
# (972596,) (243149,)
# (972596,) (243149,)
# (972596,) (243149,)
# ...
# (972596,) (243149,) 共15次
R: caret套件中trainControl(method = "LOOCV")
train_control <- trainControl(method = "LOOCV")
## 設定完train_control後,可使用train()來訓練模型,method可選擇想使用的模型
model <- train(Activity ~., data = dataset2, method = method,
trControl = train_control)
Python: sklearn.model_selection套件中LeaveOneOut
from sklearn.model_selection import LeaveOneOut
X = dataset2.iloc[:,range(0,12)]
Y = dataset2['Activity']
loo = LeaveOneOut()
for train, test in loo.split(X):
print("%s %s" % (train.shape, test.shape))
# (1215744,) (1,)
# (1215744,) (1,)
# ...
# (1215744,) (1,) 共1215745次
R: caret套件中trainControl(method = "boot", number = times)
## bootstrap with 100 resamples
train.control <- trainControl(method = "boot", number = 100)
## 設定完train_control後,可使用train()來訓練模型,method可選擇想使用的模型
model <- train(Activity ~., data = dataset2, method = method,
trControl = train_control)
Python
n_iterations = 10
for i in range(n_iterations):
train = resample(dataset2, replace=True,
n_samples=int(len(dataset2)*0.8))
test = dataset2[~dataset2.index.isin(train.index)]
X_train = train.iloc[:,range(0,12)]
y_train = train['Activity']
X_test = test.iloc[:,range(0,12)]
y_test = test['Activity']
print("%s %s" % (X_train.shape, X_test.shape))
#(972596, 12) (546428, 12)
#(972596, 12) (546540, 12)
# ...
#(972596, 12) (546729, 12) 共10次

